Автор: Владимир Шитиков
В одном из предыдущих сообщений были определены основные понятия, преимущества и недостатки деревьев классификации и регрессии, которые являются одним из наиболее популярных методов решения многих практических задач (Breiman at al., 1984; Quinlan, 1986). По своей сути деревья используют "наивный подход" (naive approach) в том смысле, что исходят из предположения о взаимной независимости признаков. Поэтому модели регрессионных деревьев статистически наиболее работоспособны, когда мультиколлинеарность в комплексе анализируемых переменных выражена незначительно.
Алгоритм CART (Classification and Regression Trees) рекурсивно делит исходный набор данных на подмножества, которые становятся все более и более гомогенными относительно определенных признаков, в результате чего формируется древовидная иерархическая структура. Деление осуществляется на основе традиционных логических правил вида "ЕСЛИ (А) ТО (В)", где А - некоторое логическое условие, а В - процедура разбиения подмножества на две части, для одной из которых условие А истинно, а для другой - ложно. Примеры условий: Xi == F, Xi <= V; Xi >= V и др., где Xi - один из предикторов, F - выбранное значение категориальной переменной, V - специально подобранное опорное значение (порог) количественной переменной.
На первой итерации корневой узел дерева связывается с наиболее оптимальным условным суждением, и все множество объектов разбивается на две группы. От каждого последующего узла-родителя к узлам-потомкам также может отходить по две ветви, в свою очередь связанные c граничными значениями других наиболее подходящих переменных и определяющие правила дальнейшего разбиения (splitting criteria). Конечные узлы (terminal nodes) дерева (также известны как "листья", leaves) представлены совокупностями наблюдений из обучающей выборки, полученными в результате проверки всех предыдущих условных суждений. Общее правило выбора опорного значения для каждого узла построенного дерева можно сформулировать следующим образом: "выбранный признак должен разбить множество Х* так, чтобы получаемые в итоге подмножества Х*k, k = 1, 2, ..., p, состояли из наблюдений, принадлежащих к одному классу, или были максимально приближены к этому".
Описанный процесс относится к так называемым "жадным" алгоритмам, стремящимся построить максимально "кустистое" дерево (также "глубокое дерево", deep tree). Естественно, чем "кустистее" дерево, тем лучше будут результаты его тестирования на обучающей выборке, и, скорее всего, хуже - на незнакомых наблюдениях. Поэтому построенная модель должна быть еще и оптимальной по размерам, т.е. содержать информацию, улучшающую качество прогноза, и игнорировать ту информацию, которая его не улучшает. Для этого обычно проводят "обрезание" дерева (tree pruning) - отсечение ветвей там, где эта процедура не приводит к серьезному возрастанию ошибки.
Невозможно подобрать объективный внутренний критерий, приводящий к хорошему компромиссу между безошибочностью и компактностью модели, поэтому стандартный механизм оптимизации деревьев основан на перекрестной проверке (Loh & Shih, 1997). Для этого обучающая выборка разделяется, например, на 10 равных частей: 9 частей используются для построения дерева, а оставшаяся часть играет роль проверочной выборки. После многократного повторения этой процедуры из некоторого набора деревьев-претендентов с приемлемым (для решаемой задачи) разбросом значений того или иного критерия качества модели, выбирается дерево, показавшее наилучший результат в ходе перекрестной проверки.
Существует несколько алгоритмов построения деревьев, основанных на различной логике и критериях оптимизации. Функция rpart() из одноименного пакета выполняет рекурсивный выбор для каждого следующего узла таких опорных значений, которые приводят к минимальной сумме квадратов внутригрупповых отклонений Dt для всех t узлов дерева. Для оценки качества построенного дерева T в ходе его оптимизации используется следующая совокупность критериев:
- СС(T) = Σ(Dt + λt) - штраф на сложность модели (cost complexity), включающий штрафной множитель λ за каждую неотсечённую ветвь;
- D0 - девианс для нулевого дерева (т.е. оценка разброса в исходных данных);
- Cp = λ/D0 - относительный штраф на сложность модели (также известен как "статистика Мэллоу", Mallow's Cp);
- RELer = ΣDt /D0 - относительная ошибка обучения для дерева из t узлов;
- CVer - ошибка перекрестной проверки (например, с разбиением на 10 блоков), также отнесенная к девиансу нуль-модели D0. Как правило CVer больше, чем RELer;
- SE - стандартное отклонение для ошибки перекрестной проверки.
Оптимальным обычно считается дерево, состоящее из такого количества ветвей t, для которого сумма (CVer + SE) является минимальной.
В качестве примера рассмотрим построение дерева CART, прогнозирующего обилие водорослей группы a1 в зависимости от гидрохимических показателей воды и условий отбора проб в различных водотоках (см. описание этих данных в сообщении, посвященном алгоритмам восстановления пропущенных значений). Сначала воспользуемся пакетом rpart. Обычно при построении деревьев регрессии применяется двухшаговая процедура: функция rpart() устанавливает связи между зависимой и независимыми переменными и формирует бинарное дерево, а функция prun() выполняет обрезание лишних ветвей:
library(DMwR) library(rpart) data(algae) algae <- algae[-manyNAs(algae), ] # Удаляем две записи с NA (rt.a1 <- rpart(a1 ~ ., data = algae[, 1:12])) n = 198 node), split, n, deviance, yval * denotes terminal node 1) root 198 90401.290 16.996460 2) PO4>=43.818 147 31279.120 8.979592 4) Cl>=7.8065 140 21622.830 7.492857 8) oPO4>=51.118 84 3441.149 3.846429 * 9) oPO4< 51.118 56 15389.430 12.962500 18) mnO2>=10.05 24 1248.673 6.716667 * 19) mnO2< 10.05 32 12502.320 17.646880 38) NO3>=3.1875 9 257.080 7.866667 * 39) NO3< 3.1875 23 11047.500 21.473910 78) mnO2< 8 13 2919.549 13.807690 * 79) mnO2>=8 10 6370.704 31.440000 * 5) Cl< 7.8065 7 3157.769 38.714290 * 3) PO4< 43.818 51 22442.760 40.103920 6) mxPH< 7.87 28 11452.770 33.450000 12) mxPH>=7.045 18 5146.169 26.394440 * 13) mxPH< 7.045 10 3797.645 46.150000 * 7) mxPH>=7.87 23 8241.110 48.204350 14) PO4>=15.177 12 3047.517 38.183330 * 15) PO4< 15.177 11 2673.945 59.136360 *
Приведенной выше командой мы построили полное дерево из 9 узлов и 10 листьев, обозначенных символом *. В каждой строке представлены по порядку: условие разбиения, число наблюдений, соответствующих этому условию, девианс (в данном случае - это эквивалент суммы квадратов отклонений от группового среднего) и среднее значение отклика для выделенной ветви. Например, перед первым разбиением общее множество из 198 наблюдений имеет среднее значение m = 16.99 при девиансе D = 90401. При PO4 >= 43.8 это множество делится на две части: 2) 147 наблюдений (m = 8.98, D = 31279) и 3) 51 наблюдение с высоким уровнем обилия водорослей (m = 40.1, D = 22442). Дальнейшие разбиения каждой из этих двух частей аналогичны.
Разумеется, лучший вариант - представить дерево графически. Популярны три варианта визуализации с использованием различных функций: plot(), prettyTree() из пакета DMwR и prp() из чрезвычайно продвинутого пакета rpart.plot:
prettyTree(rt.a1, compress = TRUE)

printcp(rt.a1) Variables actually used in tree construction: [1] Cl mnO2 mxPH NO3 oPO4 PO4 Root node error: 90401/198 = 456.57 n= 198 CP nsplit rel error xerror xstd 1 0.405740 0 1.00000 1.01753 0.13131 2 0.071885 1 0.59426 0.76097 0.12507 3 0.030887 2 0.52237 0.73959 0.12512 4 0.030408 3 0.49149 0.68751 0.11861 5 0.027872 4 0.46108 0.67415 0.11851 6 0.027754 5 0.43321 0.67136 0.11856 7 0.018124 6 0.40545 0.64653 0.11017 8 0.016344 7 0.38733 0.66502 0.11160 9 0.010000 9 0.35464 0.70171 0.11799
Функция rpart() и другие функции из этого пакета имеют собственные возможности выполнить перекрестную проверку и оценить ее ошибку при различных значениях штрафа на сложность модели cp (внимание: ваши результаты могут незначительно отличаться от приведенных в силу эффекта генератора случайных чисел!):
# Снижаем пороговые значения штрафа с шагом .005 rtp.a1 <- rpart(a1 ~ ., data = algae[, 1:12], control = rpart.control(cp = .005)) # График изменения относительных ошибок от числа узлов дерева plotcp(rtp.a1) with(rtp.a1, {lines(cptable[, 2] + 1, cptable[, 3], type = "b", col = "red") legend(locator(1), c("Ошибка обучения", "Ошибка крос-проверки (CV)", "min(CV ошибка)+SE"), lty = c(1, 1, 2), col = c("red", "black", "black"), bty = "n") })

На графике видно, что минимум относительной ошибки при перекрестной проверке примерно приходится на значение cp = 0.029. Выполним обрезку дерева при этом значении:
rtp.a1 <- prune(rtp.a1, cp = 0.029) prettyTree(rtp.a1)

Выполним теперь дополнительную оптимизацию параметра ср с использованием функции train() из пакета caret (подробнее см. здесь). Будем тестировать деревья регрессии при 30 значениях критерия ср, применяя к каждому из них 10-кратную перекрестную проверку с 3 повторностями (как и выше, ваши результаты могут немного отличаться от приведенных):
library(caret) cvCtrl <- trainControl(method = "repeatedcv", repeats = 3) rt.a1.train <- train(a1 ~ ., data = na.omit(algae[, 1:12]), method = "rpart", tuneLength = 30, trControl = cvCtrl) 184 samples 15 predictors Resampling: Cross-Validation (10 fold, repeated 3 times) cp RMSE Rsquared RMSE SD Rsquared SD 0 15.8 0.45 3.19 0.18 0.0139 15.8 0.446 3.23 0.189 0.0279 15.6 0.459 3.5 0.208 0.0418 15.1 0.474 3.64 0.216 0.0557 15.2 0.468 3.79 0.216 0.0697 15.4 0.454 4.01 0.234 0.0836 15.7 0.451 4.18 0.242 0.0976 16.2 0.428 4.08 0.214 0.111 16.4 0.403 3.86 0.211 ... 0.362 16.4 0.411 3.84 0.213 0.376 17 0.388 4.04 0.203 0.39 17.5 0.374 3.84 0.201 0.404 19.4 0.236 2.93 0.166 RMSE was used to select optimal model using smallest value. The final value used for the model was cp = 0.0418. plot(rt.a1.train)

rtt.a1 <- rt.a1.train$finalModel prettyTree(rtt.a1)

При cp = 0.0418 было получено существенно урезанное дерево, которое, правда, значительно потеряло в своей объясняющей ценности (с т.з. биологических механизмов, определяющих обилие водорослей).
Обратимся теперь к принципиально другим методам рекурсивного разбиения, представленным в пакете party. Стандартный механизм проверки статистических гипотез, который предотвращает переусложнение модели, реализован в функции ctree(), использующей метод построения деревьев на основе "условного вывода" (англ. conditional inference). Алгоритм принимает во внимание характер распределения независимых переменных и на каждом шаге рекурсивного разбиения данных осуществляет отбор несмещенного набора предикторов, используя формальный тест на основе статистического критерия Crit(tj, µj, Σj), j = 1, ..., m, где, µ, Σ - соответственно среднее и ковариация (Hothorn et al., 2006). Оценка статистической значимости этого критерия выполняется на основе перестановочного теста, в результате чего формируются компактные деревья, не требующие процедуры обрезания.
library(party) # Построение дерева методом "условного вывода" (ctree.a1 <- ctree(a1 ~ ., data = algae[, 1:12])) Conditional inference tree with 4 terminal nodes Response: a1 Inputs: season, size, speed, mxPH, mnO2, Cl, NO3, NH4, oPO4, PO4, Chla Number of observations: 198 1) PO4 <= 43.5; criterion = 1, statistic = 46.49 2)* weights = 50 1) PO4 > 43.5 3) oPO4 <= 51.111; criterion = 0.989, statistic = 10.861 4) size == {small}; criterion = 0.995, statistic = 15.311 5)* weights = 15 4) size == {large, medium} 6)* weights = 49 3) oPO4 > 51.111 7)* weights = 84 plot(ctree.a1)

Оптимизацию параметра mincriterion выполним с использованием функции train() при тех же условиях перекрестной проверки:
ctree.a1.train <- train(a1 ~ ., data = algae[, 1:12], method = "ctree", tuneLength = 10, trControl = cvCtrl) Resampling: Cross-Validation (10 fold, repeated 3 times) mincriterion RMSE Rsquared RMSE SD Rsquared SD 0.01 16 0.422 3.69 0.191 0.119 15.9 0.427 3.71 0.193 0.228 16 0.421 3.61 0.189 0.337 16 0.417 3.54 0.187 0.446 15.9 0.426 3.59 0.187 0.554 15.9 0.425 3.43 0.172 0.663 15.8 0.437 3.3 0.178 0.772 15.7 0.442 3.37 0.183 0.881 15.6 0.444 3.67 0.18 0.99 15.9 0.428 4.1 0.246 RMSE was used to select optimal model using smallest value. The final value used for the model was mincriterion = 0.881. plot(ctree.a1.train) ctreet.a1 <- ctree.a1.train$finalModel plot(ctreet.a1)
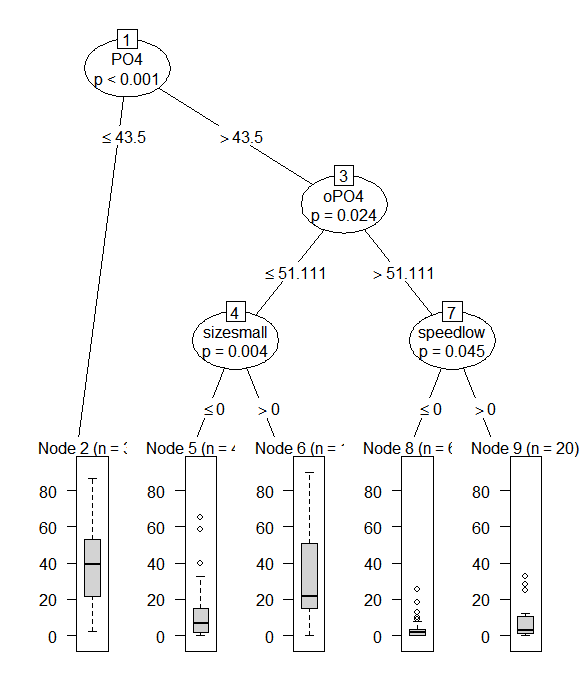
Здесь имел место обратный процесс: число узлов дерева было предложено увеличить с 7 до 9. Обратим также внимание на то, что в дереве появились категориальные переменные (размер и скорость течения реки), которые ранее были проигнорированы rpart-деревьями.
Возникает естественный вопрос: а какому из полученных четырех деревьев следует отдать предпочтение при прогнозировании? Хорошую возможность ответить на этот вопрос предоставляет нам L. Torgo, подготовивший на сайте своей книги набор данных из 140 проверочных наблюдений (см. файл Eval.txt с предикторами и Sols.txt со значениями отклика). Пропущенные значения заполним с использованием алгоритма бэггинга:
Eval <- read.table('Eval.txt', header = F, dec = '.', col.names = c('season', 'size', 'speed', 'mxPH', 'mnO2', 'Cl', 'NO3', 'NH4', 'oPO4', 'PO4', 'Chla'), na.strings = c('XXXXXXX')) Sols <- read.table('Sols.txt', header = FALSE, dec = '.', col.names = c('a1', 'a2', 'a3', 'a4', 'a5', 'a6', 'a7'), na.strings = c('XXXXXXX')) ImpEval <- preProcess(Eval[, 4:11], method = 'bagImpute') Eval[, 4:11] <- predict(ImpEval, Eval[, 4:11])
Выполним прогноз для проверочной выборки и оценим точность каждой модели по трем показателям: среднему абсолютному отклонению (MAE), корню из среднеквадратичного отклонения (RSME) и коэффициенту детерминации (Rsq = 1 - NSME , где NSME – относительная ошибка, равная отношению средних квадратов относительно
регрессии и общего среднего):
# Функция, выводящая вектор критериев ModCrit <- function (pred, fact) { mae <- mean(abs(pred-fact)) rmse <- sqrt(mean((pred-fact)^2)) Rsq <- 1-mean((pred-fact)^2)/mean((mean(fact)-fact)^2) c(MAE=mae, RSME=rmse, Rsq=Rsq) } Result <- rbind( rpart_prune = ModCrit(predict(rtp.a1, Eval), Sols[, 1]), rpart_train = ModCrit(predict(rt.a1.train, Eval), Sols[, 1]), ctree_party = ModCrit(predict(ctree.a1, Eval), Sols[, 1]), ctree_train = ModCrit(predict(ctree.a1.train, Eval), Sols[, 1]) ) Result MAE RSME Rsq rpart_prune 11.16546 16.09485 0.3828278 rpart_train 10.72834 15.36578 0.4374751 ctree_party 11.32286 16.53470 0.3486336 ctree_train 11.25551 16.40532 0.3587876
Можно с разумной осторожностью сделать вывод о том, что прогнозирующая ценность деревьев после дополнительной оптимизации функцией train() несколько возрастает, а деревья, построенные с помощью rpart(), немного точнее, чем деревья "условного вывода" ctree().
Использованные источники:
- Breiman L., Friedman J.H., Olshen R.A. et al. (1984) Classifcation and Regression Trees. Belmont (CA): Wadsworth Int. Group, 368 p.
- Quinlan J. R. (1986) Induction of Decision Trees. Machine Learning 1: 81-106
- Loh W.-Y, Shih Y.-S. (1997) Split selection methods for classification trees. Statistica Sinica 7: 815-840
- Torgo L. (2011) Data mining with R : learning with case studies. Chapman & Hall/CRC, 272 p.
- Kuhn M. (2013) Predictive Modeling with R and the caret Package
- Hothorn T, Hornik K, Zeileis A. (2006) Unbiased Recursive Partitioning: A Conditional Inference Framework. Journal of Computational and Graphical Statistics 15(3): 651-674
- Hothorn T, Hornik K, Zeileis A. ctree: Conditional Inference Trees
интересная статья
если это возможно посвятите несколько статей о временных рядах
методах анализа, оценки моделей
мне кажется это было бы очень интересно для многих
Думаю, к лету дойдем и до временных рядов (у нас уже продумана строгая последовательность серии сообщений). А пока посмотрите главу 7 в нашей книге "Рандомизация и бутстреп..." на http://www.ievbras.ru/ecostat/Kiril/Article/A32/Stare.htm Там многое есть...
Ирина Гончар
Отправить комментарий